
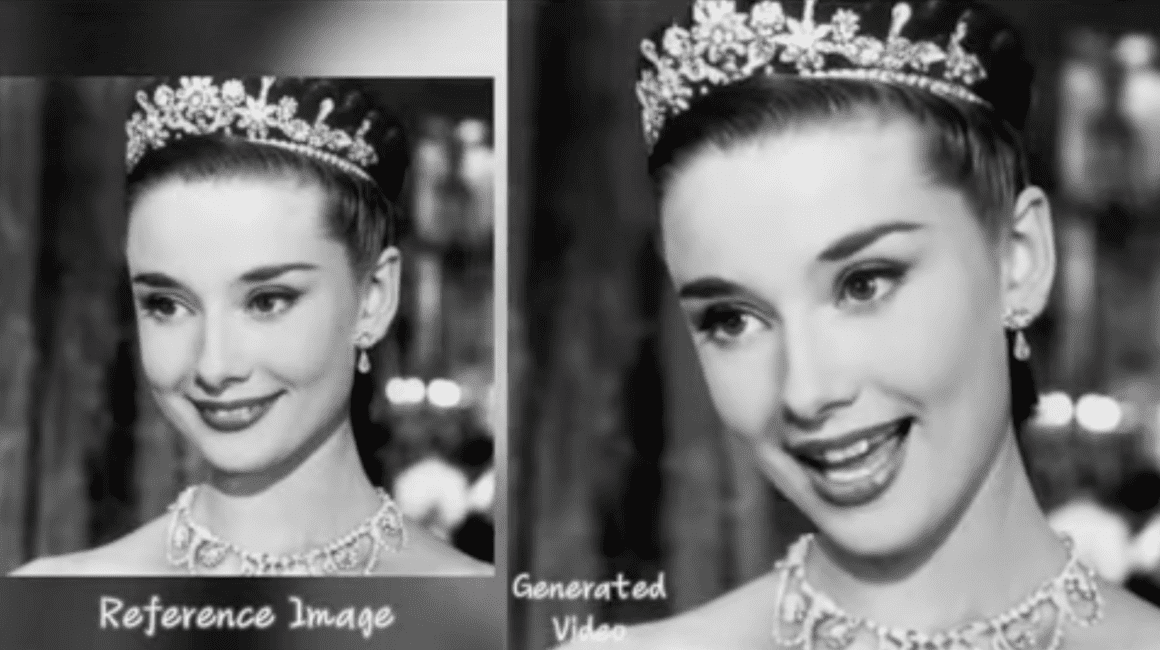
Alibaba’s venture into artificial intelligence (AI) introduces EMO: Emote Portrait Alive, an innovative technology that utilizes an audio2video diffusion model for crafting lifelike portrait videos. This groundbreaking tool redefines the creation of talking head videos, offering a precision in emotional expression far beyond what traditional methods have achieved. EMO leverages nuanced facial expressions derived from audio inputs, marking a significant leap in video generation technology.
Created by Alibaba Group’s Institute for Intelligent Computing, EMO incorporates cutting-edge diffusion models and neural networks to revolutionize talking head video production. This addresses the complex challenge of producing expressive, realistic talking head videos—a task where conventional approaches often stumble, unable to fully replicate the depth of human emotion or the subtlety of facial movements. Alibaba’s researchers have designed EMO to convert audio cues into accurate facial expressions effectively.
EMO operates through a comprehensive two-stage process that fuses audio and visual inputs to create expressive portrait videos. The initial Frames Encoding phase uses ReferenceNet to pull features from a reference image and motion frames, laying the groundwork for the dynamic portrait generation. Following this, a pretrained audio encoder processes the audio inputs, coupling them with facial region masks and multi-frame noise to generate the imagery. The Backbone Network, featuring Reference-Attention and Audio-Attention mechanisms, ensures the preservation of the character’s identity and the accuracy of their movements. Temporal Modules are then used to fine-tune the motion velocity, enabling EMO to produce vocal avatar videos that boast expressive facial animations and head movements tailored to the audio’s duration. 
Going beyond standard talking head videos, EMO introduces the capability to generate vocal avatars. With just an image and audio input, EMO can render videos that feature expressive facial and head movements across various languages, showcasing unparalleled accuracy and expressiveness. This functionality not only supports multilingual and multicultural expressions but also captures the essence of rapid rhythms, offering new possibilities for content creation, such as music videos.
Additionally, EMO’s adaptability allows it to animate spoken audio in multiple languages, giving new life to portraits of historical figures, artwork, and AI-generated characters. This broadens the spectrum for creative character portrayal, enabling interactions with iconic personalities and facilitating cross-actor performances.
Backed by an extensive audio-video dataset, EMO pushes the envelope in portrait video generation, maintaining smooth transitions and consistent identity without the need for 3D models or facial landmarks. While EMO sets new standards in expressive video creation, its dependence on the quality of input and opportunities for enhancement in audio-visual synchronization and emotion recognition suggest areas for future growth.
Ultimately, EMO: Emote Portrait Alive stands as a milestone in portrait video technology, using advanced AI to achieve an unmatched level of realism and accuracy. As it evolves, EMO is expected to expand the realms of digital communication, entertainment, and artistic exploration, changing how we interact with digital avatars and portray characters in various languages and cultures.









